Wave goodbye to output parameters, sentinel values, and endless null checking! Embrace clean, efficient error handling today by encapsulating operations that may succeed or fail in a type-safe way.
Boost Performance Fewer pointer dereferences; rely on optimized single return values
Simple API Handle success and failure scenarios with just a handful of C macros
Streamlined Error Handling Reduce the chances of incorrect or inconsistent error handling
Safe Execution Enforce valid states, eliminating risks like dangling pointers or stale data
Enhanced Readability Reduce boilerplate code to make your code easier to understand
Functional Style Avoid side effects and encourage pure, composable functions
Lightweight Keep your project slim with no extra dependencies
Open Source Enjoy transparent, permissive Apache 2 licensing
Header-Only C Library Compatible with C23 standard and modern compilers
Remarks
This library provides a cleaner, safer, and more modern approach to error handling by combining function result and error into a unified return value. It enforces correct usage at the call site, reduces the risk of bugs, and leads to more maintainable and extensible code.
TL;DR
Not a fan of reading long docs? No worries! Tune in to Deep Dive, a podcast generated by NetbookLM. In just a few minutes, you'll get the essential details and a fun intro to what this library can do for you!
Deep Dive into the Result Library
Results in a Nutshell
Result objects represent the outcome of an operation, removing the need for output parameters, sentinel values, and null checking. Operations that succeed produce results encapsulating a success value; operations that fail produce results with a failure value. Success and failure can be represented by whatever types make the most sense for each operation.
Let's use a pet store example to show how this library can simplify your code.
Start by defining some data types to represent pets.
Next, let's say you have an array of pets acting as your "database".
// Available pets in the store
staticstruct pet pets[] = {
{.id = 0, .name = "Rocky", .status = AVAILABLE},
{.id = 1, .name = "Garfield", .status = PENDING},
{.id = 2, .name = "Rantanplan", .status = SOLD}
};
Note
You'll use a function, find_pet(id), to retrieve pets by their ID. We'll skip its implementation for now.
Suppose you need to write a function to get a pet's status.
Warning
This works... until someone passes an invalid ID. If find_pet returns NULL, your code could crash unexpectedly.
To fix this, you refactor the function to return an error code and use an output parameter to "return" the pet status.
It's safer, but also clunky.
Warning
What if the output pointer is NULL? Should you return a new error code? Use assert? It's starting to feel messy.
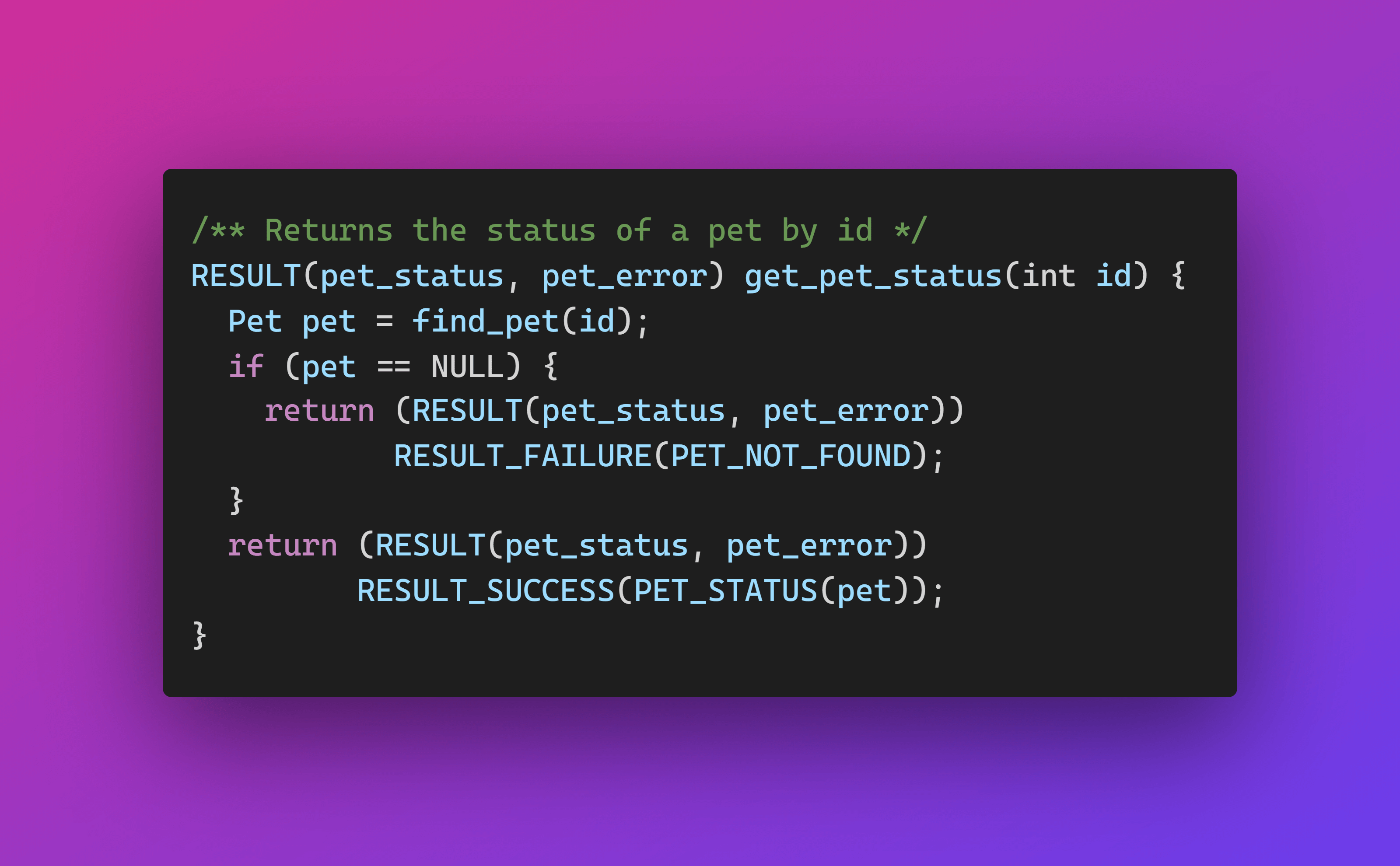
Instead of juggling pointers and error codes, you should return a Result object.
Remarks
The result encapsulates both success (pet status) and failure (error code) in one clean package. The caller immediately knows the function can fail, and you've eliminated the need for an output pointer. This is simpler, safer, and much easier to read.
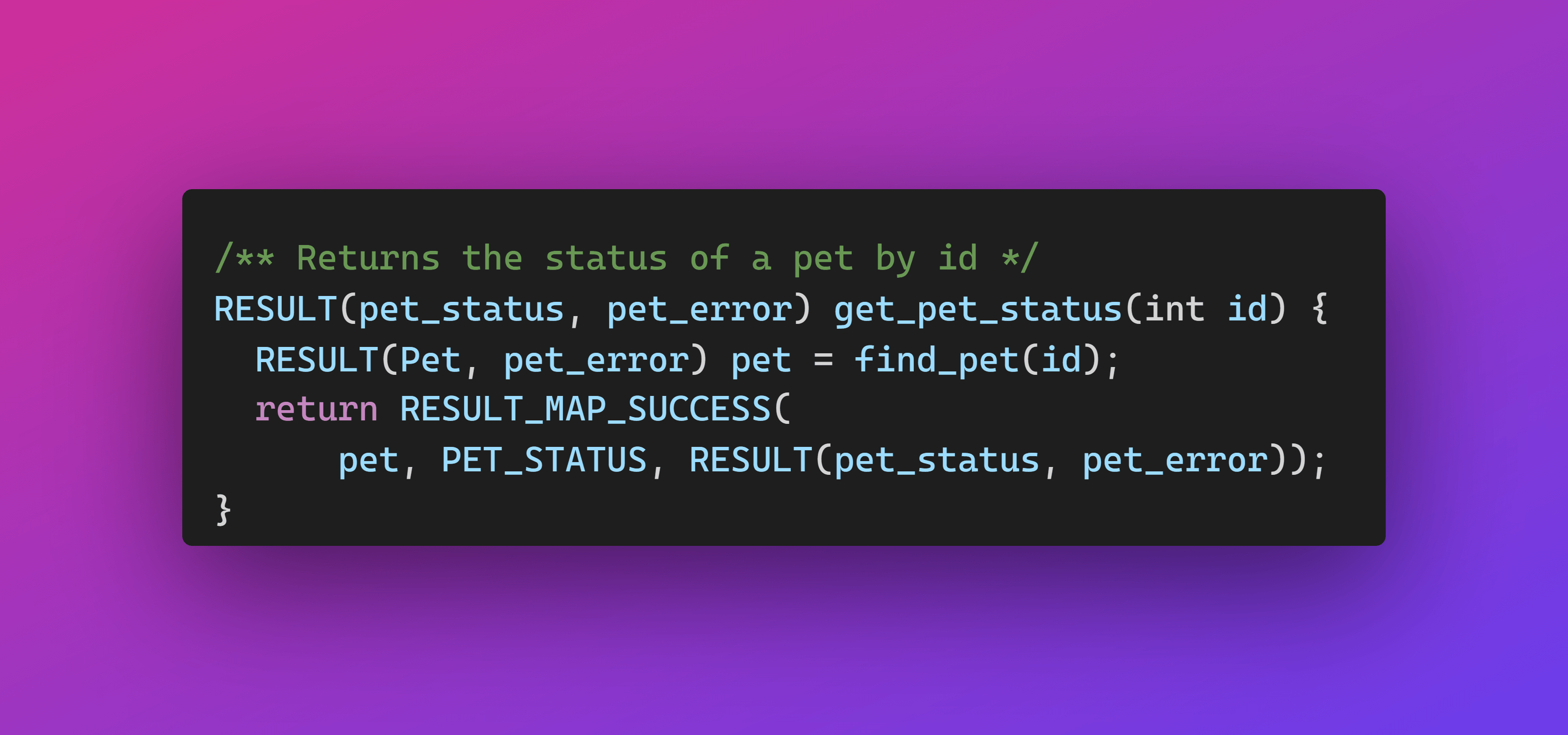
Encouraged, you refactor find_pet to return a failed result instead of NULL when a pet isn't found. Now, get_pet_status can rely on find_pet to handle errors and focus on the happy path.
Note
And just like that, your code becomes robust and maintainable. No more mysterious crashes, no awkward pointer checks. Just clean, elegant error handling.
With Results, handling success and failure feels natural, leaving you free to focus on the fun parts of coding.
Getting Started
Adding Results to Your Project
This library consists of one header file only. All you need to do is copy result.h into your project, and include it.
 Boost Performance Fewer pointer dereferences; rely on optimized single return values
Boost Performance Fewer pointer dereferences; rely on optimized single return values Simple API Handle success and failure scenarios with just a handful of C macros
Simple API Handle success and failure scenarios with just a handful of C macros Streamlined Error Handling Reduce the chances of incorrect or inconsistent error handling
Streamlined Error Handling Reduce the chances of incorrect or inconsistent error handling Safe Execution Enforce valid states, eliminating risks like dangling pointers or stale data
Safe Execution Enforce valid states, eliminating risks like dangling pointers or stale data Enhanced Readability Reduce boilerplate code to make your code easier to understand
Enhanced Readability Reduce boilerplate code to make your code easier to understand Functional Style Avoid side effects and encourage pure, composable functions
Functional Style Avoid side effects and encourage pure, composable functions Lightweight Keep your project slim with no extra dependencies
Lightweight Keep your project slim with no extra dependencies Open Source Enjoy transparent, permissive Apache 2 licensing
Open Source Enjoy transparent, permissive Apache 2 licensing Header-Only C Library Compatible with C23 standard and modern compilers
Header-Only C Library Compatible with C23 standard and modern compilers